OpenAI ने GPT-4O को बेहतर रचनात्मक लेखन क्षमता के साथ अपडेट किया, नई स्वचालित रेड टीमिंग विधि का खुलासा किया

OpenAI ने पिछले सप्ताह अपने आर्टिफिशियल इंटेलिजेंस (एआई) मॉडल को बेहतर बनाने के दो तरीकों की घोषणा की। पहले में GPT-4O (जिसे जीपीटी-4 टर्बो के नाम से भी जाना जाता है) के लिए एक नया अपडेट जारी करना शामिल है, जो कंपनी का नवीनतम एआई मॉडल है जो पेड सब्सक्राइबर्स के लिए चैटजीपीटी को सशक्त बनाता है।
कंपनी का कहना है कि अपडेट मॉडल की रचनात्मक लेखन क्षमता में सुधार करता है और इसे प्राकृतिक भाषा प्रतिक्रियाओं और उच्च पठनीयता के साथ आकर्षक सामग्री लिखने में बेहतर बनाता है। ओपनएआई ने रेड टीमिंग पर दो शोध पत्र भी जारी किए और अपने एआई मॉडल द्वारा की गई त्रुटियों को पहचानने के लिए प्रक्रिया को स्वचालित करने के लिए एक नई विधि साझा की।


OpenAI ने GPT-4O AI मॉडल को अपडेट किया
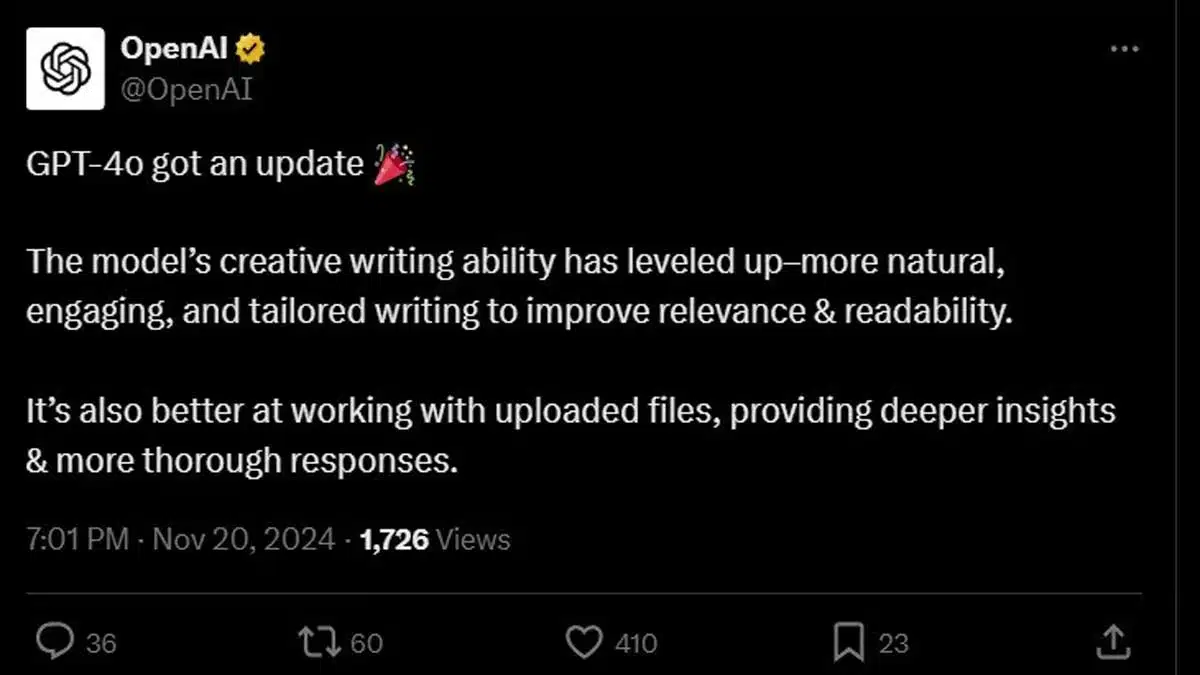
एक्स (जिसे पहले ट्विटर के नाम से जाना जाता था) पर एक पोस्ट में, एआई फर्म ने जीपीटी-4ओ फाउंडेशन मॉडल के लिए एक नए अपडेट की घोषणा की। ओपनएआई का कहना है कि अपडेट एआई मॉडल को “प्रासंगिकता और पठनीयता में सुधार करने के लिए अधिक प्राकृतिक, आकर्षक और अनुरूप लेखन के साथ आउटपुट उत्पन्न करने की अनुमति देता है।” ऐसा भी कहा जाता है कि यह अपलोड की गई फ़ाइलों को संसाधित करने और गहन अंतर्दृष्टि और “अधिक गहन” प्रतिक्रियाएँ प्रदान करने की AI मॉडल की क्षमता में सुधार करता है।
विशेष रूप से, GPT-4o AI मॉडल ChatGPT Plus सदस्यता वाले उपयोगकर्ताओं और API के माध्यम से बड़े भाषा मॉडल (LLM) तक पहुँच वाले डेवलपर्स के लिए उपलब्ध है। चैटबॉट के मुफ़्त टियर का उपयोग करने वालों के पास मॉडल तक पहुँच नहीं है।
जबकि गैजेट्स 360 के कर्मचारी नई क्षमताओं का परीक्षण करने में सक्षम नहीं थे, X पर एक उपयोगकर्ता ने अपडेट के बाद AI मॉडल में नवीनतम सुधारों के बारे में पोस्ट किया। उपयोगकर्ता ने दावा किया कि GPT-4o “परिष्कृत आंतरिक तुकबंदी संरचनाओं” के साथ एमिनेम-शैली का रैप सिफर उत्पन्न कर सकता है।
इंटरनेट ब्राउज़िंग में माहिर बनें, ChatGPT की नई शक्ति!
OpenAI ने रेड टीमिंग पर नए शोध पत्र साझा किए

रेड टीमिंग डेवलपर्स और कंपनियों द्वारा कमजोरियों, संभावित जोखिमों और सुरक्षा मुद्दों के लिए सॉफ़्टवेयर और सिस्टम का परीक्षण करने के लिए बाहरी संस्थाओं को नियुक्त करने के लिए उपयोग की जाने वाली प्रक्रिया है। अधिकांश AI फ़र्म संगठनों के साथ सहयोग करती हैं, इंजीनियरों और नैतिक हैकर्स को तनाव-परीक्षण करने के लिए प्रेरित करती हैं कि क्या यह हानिकारक, गलत या भ्रामक आउटपुट के साथ प्रतिक्रिया करता है। यह जाँचने के लिए भी परीक्षण किए जाते हैं कि क्या AI सिस्टम को जेलब्रेक किया जा सकता है।
जब से ChatGPT को सार्वजनिक किया गया है, OpenAI प्रत्येक क्रमिक LLM रिलीज़ के लिए अपने रेड टीमिंग प्रयासों के साथ सार्वजनिक रहा है। पिछले सप्ताह एक ब्लॉग पोस्ट में, कंपनी ने प्रक्रिया की उन्नति पर दो नए शोध पत्र साझा किए। उनमें से एक विशेष रूप से दिलचस्प है क्योंकि कंपनी का दावा है कि यह AI मॉडल के लिए बड़े पैमाने पर रेड टीमिंग प्रक्रियाओं को स्वचालित कर सकती है।

OpenAI डोमेन में प्रकाशित, पेपर का दावा है कि रेड टीमिंग को स्वचालित करने के लिए अधिक सक्षम AI मॉडल का उपयोग किया जा सकता है। कंपनी का मानना है कि AI मॉडल हमलावर के लक्ष्यों पर विचार-मंथन करने, हमलावर की सफलता का आकलन कैसे किया जा सकता है और हमलों की विविधता को समझने में सहायता कर सकते हैं।
इस पर विस्तार करते हुए, शोधकर्ताओं ने दावा किया कि GPT-4T मॉडल का उपयोग उन विचारों की सूची पर विचार-मंथन करने के लिए किया जा सकता है जो AI मॉडल के लिए हानिकारक व्यवहार का गठन करते हैं। कुछ उदाहरणों में “कार कैसे चुराएँ” और “बम कैसे बनाएँ” जैसे संकेत शामिल हैं। एक बार विचार उत्पन्न हो जाने के बाद, संकेतों की एक विस्तृत श्रृंखला का उपयोग करके ChatGPT को धोखा देने के लिए एक अलग रेड टीमिंग AI मॉडल बनाया जा सकता है।
वर्तमान में, कंपनी ने कई सीमाओं के कारण रेड टीमिंग के लिए इस पद्धति का उपयोग शुरू नहीं किया है। इनमें AI मॉडल के उभरते जोखिम, जेलब्रेकिंग या हानिकारक सामग्री उत्पन्न करने के लिए AI को कम-ज्ञात तकनीकों के संपर्क में लाना, और AI मॉडल के अधिक सक्षम हो जाने पर आउटपुट के संभावित जोखिमों का सही ढंग से आकलन करने के लिए मनुष्यों में ज्ञान की उच्च सीमा की आवश्यकता शामिल है।
अन्य ख़बरों के लिए यहाँ क्लिक करें